Systems Design: A General Rubric
Functional Requirements
- Whatever the application should support
- Example: upload videos, follow users, like videos, comment on videos
Nonfunctional Requirements
- Consistency: is eventual consistency ok? Then we can probably use read replicas and support more read throughput
- Availability: Must be five 9’s? Then will need multiple datacenters and potentially eventual consistency for replicatoin
- Latency: How many ms of latency? Will need CDN to reduce latency
Estimates
- Number of users
- Data size (per request, total, per second, per hour, per day)
Data Model
API Endpoints
- POST: uploadVideo
- GET: viewFeed
Bottlenecks
- Database usually the bottleneck
- Pick a database that will be most performant depending on the data access patterns (read v. write ratio, normalized or denormalized ok)
- Shard by geo
- Cache in front of DB
- Read only replicas
- Ways to work with hot keys (celebrity accounts, likes counters: see Twitter, Instagram)
Examples
TinyURL
500 million URLs /month 30 billion URLs * 100 bytes = 3 trillion bytes -> 3 billion KB -> 3 million MB -> 3,000 GB -> 3 TB 500M/month -> 20M/day -> 1M/hour -> 300/s. 10x peak -> 3K wps. One DB can handle URL shortener service behind load balancer Generating Short, random and readable Length: 7 chars, 62 chars to choose: [A-Z, a-z, 0-9]. This is base62 encoding. To create a short link, store a global incrementing value and convert it to base 62, then increment it (if current value is 125, distribute that across 62^0, 62^1, etc. and then set values to 0:0, 1:1…10:a, 11:b…36:A, 37:B Then always check if it’s already used just to be sure 62^7 = 3500 billion URLs = 110 years to run out Could also do log62(30 billion) 62 to what power gives 30 billion, this should be length of shortlink Read:write 100:1 then 30k rps Need read replicas. 10k peaks means 300k rps Mysql 10k selects per second so at least 3 read replicas Caching layer for additional scaling. Redis can handle 100k rps Hottest URLs 1% of total = 30 GB, can store each on Redis
Uber
Driver connects via websocket to deliver location payload every 5s latitude, longitude, direction, driver_id 500k active drivers, average shift of 6 hours, 4 shifts per day 125k drivers active at any moment, message every 5 seconds, 25k RPS on average Peak x2 = 50k, x4 = 100k, x10 = 250k Rule of thumb: 5k writes/s for any DB node How to handle writing this location data? Scale reads with read replicas, scale writes with sharding Shard by geo (will get country hot spots)? custom areas (will need to maintain, update areas) - would need driver location service that takes coordinates of driver plus shard location service to find shard? Use Uber H3 geolocation library (edge free) - hexagons of equal size, each mapped to a shard. Riders 10M active 5 opens of app/day = 50M opens a day Refresh driver locations every 5 s, average session is 1 minutes = 12 refreshes 50M * 12 = 600 M requests/day = ~7k requests per second Postgres offers geolocation queries
Web crawler
Overall design: Content fetcher uses headless browser, sends content to indexing service and a url extractor service, url extractor sends urls to prioritiser after checking with Redis to see if it’s a new URL, prioritiser checks with redis to see if domain has already been crawled recently, if so add to postponed task queue, if not send to content fetcher. If indexing service sees new content, inform update notifier service which tells redis that content has updated, which sets a different update frequency value for that site Queue to process URLs, queue to send page content to an indexing service DNS service close to content fetcher service to serve faster DNS queries Headless browser to make sure content is rendered (React componenents need additional API request to fill in data) Interested in host, path and parameters of URL How often to check a site? How often to check subdomain of a site? Different rates Already seen URL or not? Use a bloom filter to hold all urls we have seen. 1.5B sites -> 50 GB RAM -> 1 false positive in million = 15k pages never indexed. High throughput, low consistency. Maybe better to use Redis Average URL - 50 bytes. 15B URLs - 700 GB (a lot of RAM) - so need to shard Redis - 70 shards. Medium throughput, medium consistency Could use regular relational DB, lower throughput, higher consistency
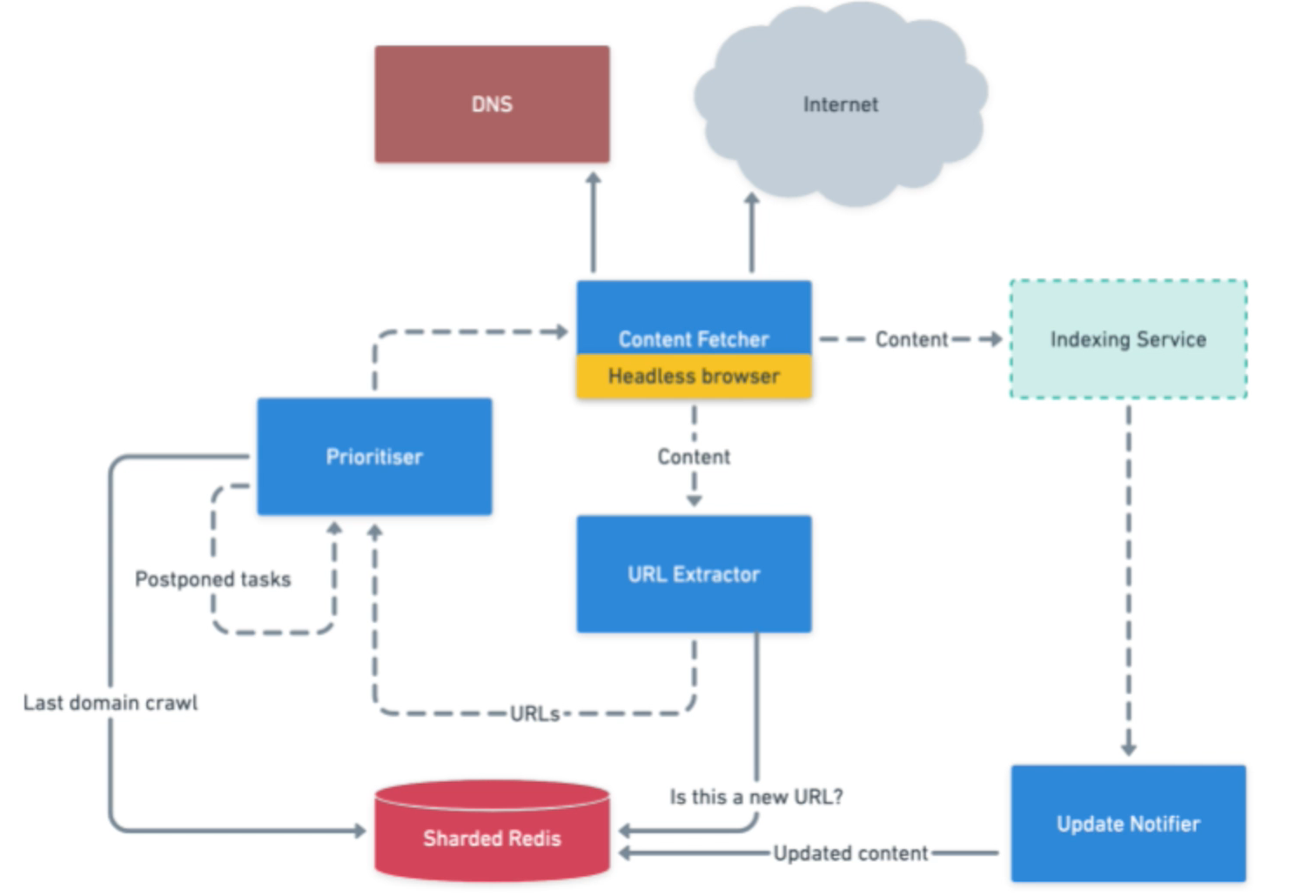
Key takeaways
Ebay
Bids service must be serialized (queue) to make sure each is evaluated in order (could have situation where a bid at $3 and a bid at $5 arrive at the same time but $3 bid is processed first, and $5 bid is rejected because of race condition in DB - if $5 bid checks to make sure it is only processed at the item’s current price) Use websockets or polling to inform client of latest price and bids
Groupon
How many active users? How many coupons? 100M users, 10M coupons, 10 minutes to give away Basic solutions: Coupons service, user id, if user in coupons DB, return coupon ID, else select count(*) from coupons, if count > max, return sorry, else insert into coupons the users id and return the coupon id How to solve concurrency issue if two users request coupon at same time Queue: Coupons service checks if the user’s coupon exists, if not send a request to write a new coupon to a queue that then writes to the DB, queue consists of single consumer that actually writes to db 100M users in 10 minutes == 20K active users per second. If 80m users arrive in first minute, 1.2M users per second Prepopulate DB with null values for 10 m coupons, this way the Database handles locking for us: When user wants coupon, select * from coupons where userid = ?, if row exists return couponid, else update coupons set userid = ? where uuid = null limit 1. If failed, return sorry, else congratulations This way the DB will only set the 10 m coupons we determined (by using sql UPDATE instead of INSERT) Layer 7 load balancer to match users to the same coupons service and same sharded coupon db Each service has an in memory cache of issued coupons and queue for writes Distribution a little bit unfair, one DB could have unissued coupons for users with ids ending in certain value
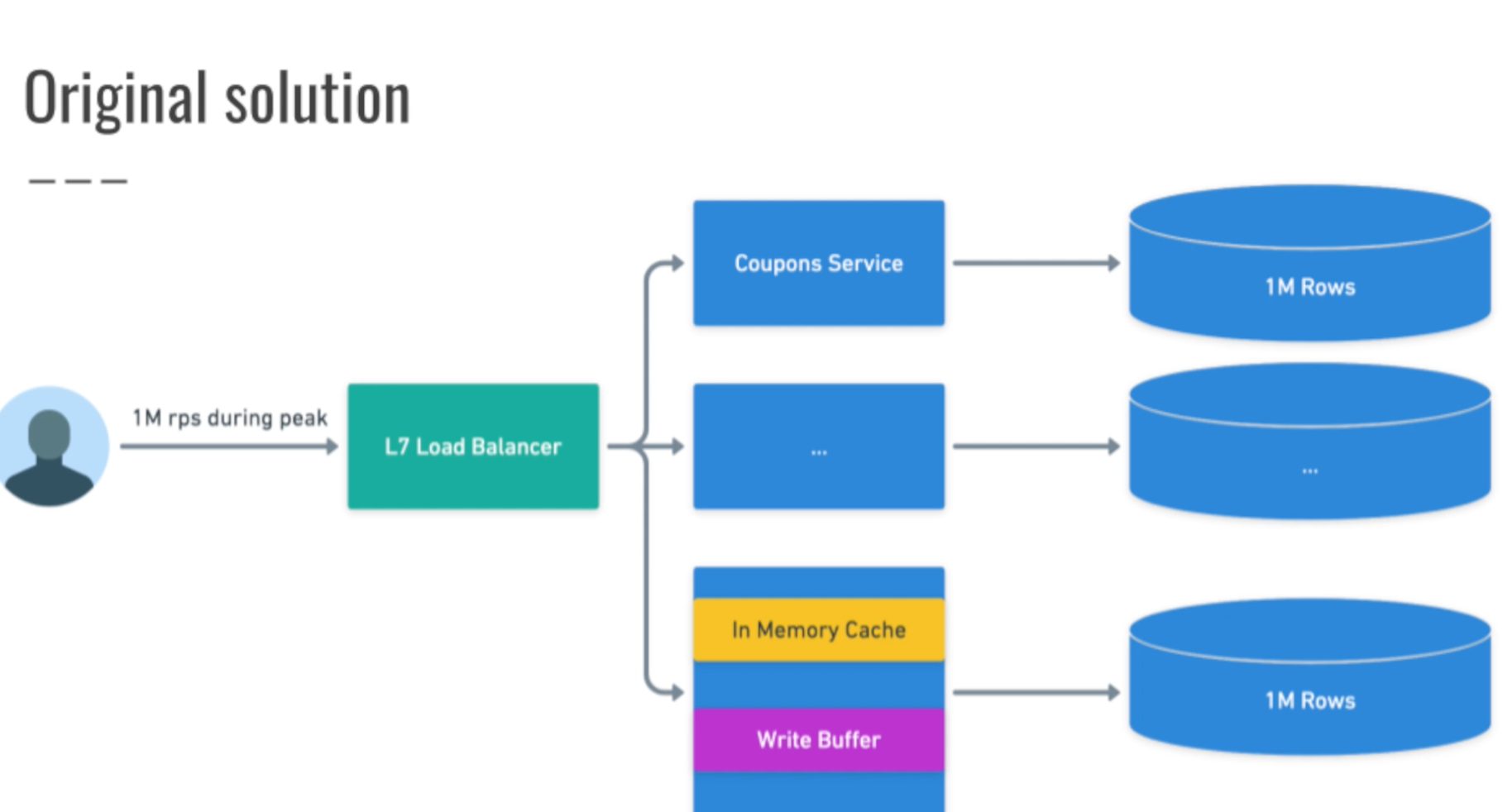
Key takeaways
- avoid concurrency issues by relying on database to lock rows. Use UPDATE instead of INSERT
- use layer 7 load balancing to match users to the same service backed by the same database. Basically sharding
- use an in memory queue and in memory counter in the coupon service to keep track of number of coupons issued, once it reaches a limit, no need to query DB. Can easily restore the count from the DB. Queue would be lost (unfair tradeoff)
Chat application
- 100 million active users, 1M chats, 1 billion messages/day, mobile and web, no group chats
- 12K messages/second (12k inserts)
- PUT request, GET request
- DB: from_user, to_user, message, sent_at
- SELECT * from messages where (user = ? or user = ?) sort by sent_at desc
- create index on messages(from_user_id, to_user_id)
- Websockets means fewer requests
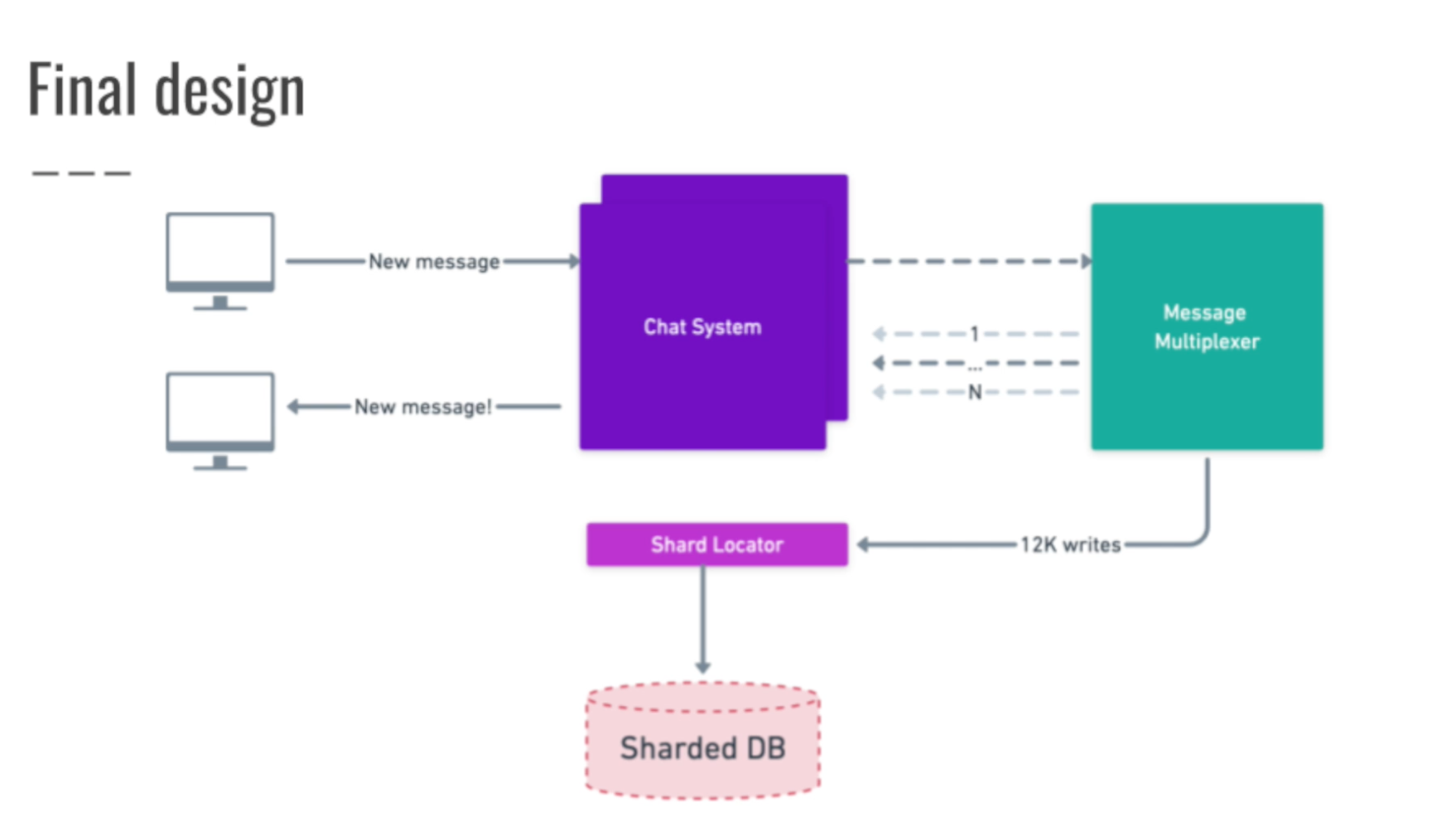
- shard messages by hashing sender and receiver. Sort pair first to make sure to produce same hash! shard locator takes 12k writes, 200k reads per second
- each new message sent to message router service via a queue, router sends the message out to websockets handler via another queue (several queues handling messages for many websocket handlers per queue), sends to user, it also send the message to the shard locator service which writes to the correct db
POST /tweets Write buffering and batching 100 bytes per tweet - 86 GB per day 31 TB/year total storage Scaling reads:
- read replicas (20 - 50k reads per second)
- sharding
- pre cache service producing cached feeds